
Amiga forum / AmigaOS 4.x / OpenGL - postępy prac
Czytasz wątek: OpenGL - postępy prac
-
konrad
Nieaktywny użytkownik starego forum
-
OpenGL - postępy prac wysłany: 2011-04-09 10:56
Na ten projekt wiele osób czeka od dawna. 3D na Amidze sięga bowiem czasów Amigi klasycznej. Takie API jak Warp3D czy MiniGL to naprawdę stare technologie i maks co się z nich dało wycisnąć to port Quake 3 oraz Blender. Artykuł The State of OpenGL on AmigaOS napisany przez twórców sysemu Amigi rzuca trochę światła na rozwiązania, których będą amigowcy używać w przyszłości. Szczegóły implementacji oraz postępy prac zbierane z sieci postaramy się umieszczać w tym wątku, żeby było wiadomo gdzie jest i dokąd zmierza świat trzech wymiarów na Amidze.
Na początek wrzucam kilka ciekawych wypowiedzi Hansa Joerga Friedena z amigans.net na temat amigowego 3D przyszłości:
@Rogue
The point of the whole exercise is exactly that:
- Get more speed by being able to use Shaders, hardware accelerated Transform/Clipping/Lighting, and improved transport mechanisms provided by the hardware.
- Get a full OpenGL implementation as opposed to an incomplete MiniGL
- Get access to the new features like GL Shader Language.
- Get access to the latest hardware that can be supported.
Having said that, Gallium3D does not support anything below R300 (which means that 9xxx and 7xxx cards are not supported by it), which is the reason why we opted for a driver architecture that allows for non-Gallium3D drivers. The initial version will probably lack support for these cards, but we'll be looking into that problem ASAP - this might take the form of a generic Warp3D driver, or trying to adapt the old DRI drivers.
Right now, this is not the focus though. The focus is on finalizing the infrastructure and the first software-only AMGL driver. We're looking at the end of this or the next week for that.
Gallium needs Shader Model 3 or better. FWIW, some of the new cards like Radeon R500 do not even have a fixed-function pipeline anymore, so yes, it is most likely using shaders for these all the time.
I am not sure why you are making such a big deal out of this. As I explained, our interface allows for non-Gallium3d drivers, specifically for this reason. There is no need to try and support and unsupported card in gallium3d if you can make it work with a standard driver.
And how do you get the idea there will be two drivers for the same card?
You need to get away from the mindset that Gallium is something you will even notice. You will be using OpenGL. On the Amiga, this means primarily "opengl.library", but since some specific init code is required, there is a libGL.a that will take care of opening the library, so in the end, yes, you only link with -lGL and nothing else.
The only differences are for example how you create a context. In MiniGL, you did something like
cc = mglCreateContext (blah blah blah).
With AMGL, you would do
cc = IOpenGL->CreateContext( blah blah blah).
That's it.
The point I was trying to make the whole time with the blog entry was that there is NO difference whether the system picks a Gallium based driver or something else. As a matter of fact, you will neither notice nor have any influence on what driver gets picked. If you feed it a bitmap, it will look for the driver that can render into this bitmap... hardware-accelerated if at all possible. If it finds a driver that can, it loads the driver and uses it from that moment on for your application (or rather for this bitmap. You can have multiple contexts at the same time). If it doesn't, it will fall back to software rendering. That process however is nothing you have any influence on. All you need to know about this is that you have to create a context just like in MiniGL. Everything else is handled by the system.
I used to have a Radeon 9800, IIRC it worked on the Pegasos. That one has an R300 chip and is supported by Gallium3D.
What does the Radeon 9200/9250 have to do with Sam440/460? The latter has a PCIe slot which can use a Radeon HD.
For other machines, a Radeon 9800 is an option. But yes, anything before Radeon HD is "older" by all means.
Warp3D and MiniGL will not stop working, and as a matter of fact I was thinking about turning the MiniGL source code into an OpenGL driver under the new model. Right now, this is not the focus however. The focus is to provide a decent new graphics architecture and OpenGL for everything we *can* achieve. Supporting new modern cards is, right now, more important than updating support for the old cards. They will still work as they do now, and might or might not get updated to the new standard.
Let me reiterate:
- Supporting new hardware is the prime focus
- Supporting a fully hardware-accelerated OpenGL is the prime focus.
- Supporting older Radeons (pre-R300) is not the focus since we already have support for them, even if that support is lacking.
- Radeons before R300 are not supported by Gallium and hence will take considerably more effort to support with a full driver.
- All platforms except for the Classic and Micro-Ai can be retrofitted with more modern Radeons. That includes AGP versions of the Radeon R300 (like a Radeon 9800) or PCI versions of these cards.
- An card like a X1650 costs 25 Euros.
There is really not more to say about this topic. I think the above pretty much sums it up. As I said, most of the platforms we support can be retrofitted with "better" cards. We might take a look at the issue with MicroA1 later on (note: the word 'might') and see if we can make things work for those as well. Other than that: See above.
-
mufa
Nieaktywny użytkownik starego forum
-
OpenGL - postępy prac wysłany: 2011-04-09 13:30
@konrad
3D na Amidze sięga bowiem czasów Amigi klasycznej. Takie API jak Warp3D czy MiniGL to naprawdę stare technologie
Skoro przypomnialeś stare czasy, to mały rys historyczny, dotyczący rozwoju Warp3D. Może komuś się przyda, tym bardziej że nawet Wikipedia w tym względzie za wiele nie mówi.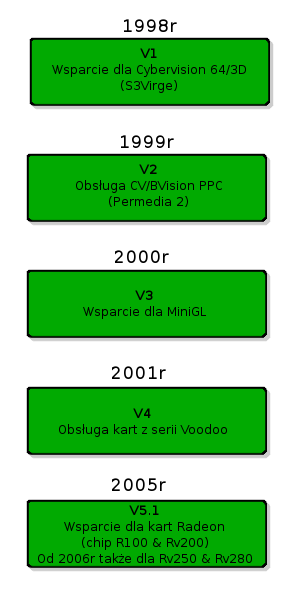
-
konrad
Nieaktywny użytkownik starego forum
-
Re:OpenGL - postępy prac wysłany: 2011-06-09 09:22
Karl Churchill jeden z systemowych deweloperów zajmujących się amigowym 3D o tym dlaczego Warp3D musi odejść. Cytaty z AW.net.
@Karlos
Long term, the best way to speed up Radeon is, I'm sorry to say, move away from Warp3D as a driver layer and to something more OpenGL oriented. In the absence of Gallium3D support (I think R300 is the miniimum there), Mesa might be a good choice. Whatever you pick, Warp3D can be realised as a thin layer interface on top for older applications that use it directly, whereas applications requiring OpenGL can use whatever has replaced it.
Allow me to explain. The biggest problem with Warp3D is that it is a rasterizer only. There's simply nothing in the existing design beyond rendering lists of already computed geometry. For my old applications, this was perfect. I was using it mostly for 2D and adding any additional layers of transformation (even if it was only applying an identity matrix) would have been an unwarranted waste of clock cycles
However, presently most of the 3D applications we are using are based around MiniGL and as such you need a full graphics pipeline. MiniGL implements all the transformation, clipping and lighting in software and then passes the computed vertices over to Warp3D for rasterization, since that's all that Warp3D actually provides. The Radeon chips we are now using are capable of doing so much more and as a result the Warp3D API is simply holding them back.
For faster 3D, you absolutely want something which is passing the scene vertices over to the card, where they are held in reusable VRAM buffers (or at least in DMA accessible memory) and all the necessary transformation is done by the graphics chip.
OpenGL fully hides the implementation from you, so the potential of hardware that is capable of the above can be realised.
Until a newer 3D architecture is in place however, it would be nice to improve what we have. On which note, you'll be happy to hear I already submitted my first R200 bugfix, the UBYTE based vertex colour formats had a channel transposition bug...
The Permedia2 driver itself presently has that limitation too. I plan to rewrite the texture handling at some stage anyway, for two reasons. First of all, there is a really irritating and long lived bug somewhere (not necessarily in the driver) that is causing textures in VRAM to get crapped on, particularly in low VRAM situations. Rewriting the texture handling code would be tantamount to giving it a really good kick to see what shakes loose.
Secondly, the debug build of the driver has a profiler in it that I created to measure (at least as far as you can with the EClock) how much time has been spent in certain functions and how often they are called. Stats are dumped to the debug log when the W3D_Context instance is destroyed. I noticed that texture uploads are pretty expensive.
Now, there are several contributing factors to this expense that a refactor might mitigate. First of all, there are two conversion steps. The first one happens when you ask Warp3D to use a texture. The driver creates a private copy of the texel data in the closest hardware-supported format for the format requested. In some cases, that's not necessary, but a copy is created nevertheless. The Warp3D API documentation says that texel data provided by the application should be considered locked and not be freed until you've released the texture, so that copy step seems redundant when the formats are directly compatible.
Anyway, the second conversion happens during upload. If the texture is wider than 32 pixels, it is transformed into a subpatched representation that aims to make neighbouring texels (in the 2D sense) as close together in memory as possible as this speeds up sampling during filtering. The existing code to do this operates on the entire texture map and is not trivially converted to work only on a small area. That's why in the Permedia2 case, subimage updates cause the whole texture to be re-uploaded.
It struck me that if the subpatch conversion code is reworked to operate on a rectangular subsection (for subimage) then it could also be moved into the first step when textures are converted to device format. The redundant copy that is presently created where texture formats match would no longer be redundant, it would be the subpatched representation of that data. Uploading the entire texture to VRAM could then be done quite quickly, using sequential transfers as wide as possible rather than writing scattered texels individually over the whole address range (this is what subpatching does to your linear array of texels).
For subpatching, after a sub image update, we'd have a bunch of seemingly random texels to update on the graphics card. What I then thought about was having a "bitplane" in which each texel is represented by a bit. When a rectangular area is subpatched, bits are set at the corresponding offset. This bitplane is then scanned sequentially as bytes and wherever a bit is set in any byte, the entire span of 8 texels covered by that byte are transferred sequentially to the VRAM. As long as the private texture is aligned to an 8-byte boundary, this transfer can be made to work using 64-bit double transfers.
This could give a decent speed increase for sub image uploads. First of all, the subpatching happens only on the rectangular area required (which is also in a cacheable area of RAM) and you get the widest possible bus transfers, arranged sequentially (rather than scattered as they are currently).
I wanted to refactor it also because I added texture usage statistics to the profiler and have observed that the LRU cache is not necessarily the best strategy for the Permedia2, which is almost always running out of VRAM. The problem with the strategy as it stands is that textures are freed based purely on when they were last used and not how often they are used or how big they are. This means that once you reach the stage where texture swapping starts to happen, you'll end up in a cyclic process in which every texture is eventually freed and re-uploaded in a queue which is rather bad for performance. Ideally, you should free infrequently used textures rather than the one that was just last in the queue. There are various intriguing algorithms to try for this one, but anything too complicated may end up being more of a slow down than the existing one.
So anyway, what you can take from this essay is that there are plenty of interesting things left to try for this driver, let alone any of the others
- Menu
- Baza wiedzy
- AmigaOS.pl